
Dynamo DB 설계 모범 케이스 분석
스터디 배경
테이블의 변경 히스토리를 저장하기 위해 DynamoDB를 사용하는 것이 좋다고 판단됌. 로그 데이터이기 때문에 데이터들의 일관성 문제가 없으며 많은 데이터를 효율적으로 저장하고 쿼리할 수 있기 때문.
개념
https://yogae.github.io/aws/2018/12/06/dynamodb_summary.html
https://docs.aws.amazon.com/ko_kr/amazondynamodb/latest/developerguide/SecondaryIndexes.html
기본키
- 파티션 키
- 내부 해시 함수에 대한 입력으로 사용되는 키
- 파티션 키로만 구성되어 있는 테이블에서는 동일한 파티션 키 값을 가질 수 없음.
- 파티션 키 및 정렬 키 (복합 기본키)
- 동일한 파티션 키 값을 가질 수 있으며, 두 아이템의 정렬키 값을 달라야함.
- 파티션 키가 동일한 모든 항목은 정렬키 값을 기준으로 정렬
- 파티션 키
보조 인덱스
- 글로벌 보조 인덱스
- 파티션 키 및 정렬키가 기본테이블의 파티션/정렬키와 다를 수 있는 인덱스
- 모든 글로벌 보조 인덱스는 파티션 키가 있어야 하며, 선택사항으로 정렬키를 가질 수 있음.
- 글로벌 보조 인덱스
모든 파티션에서 전체 테이블을 쿼리
- 로컬 보조 인덱스
- 기본 테이블과 파티션 키는 동일하지만, 정렬 키는 다른 인덱스
- 모든 로컬 보조 인덱스에는 기본 테이블의 파티션 및 정렬키가 자동적으로 포함 된다.
- 파티션 키 값으로 지정한 대로 단일 파티션을 쿼리할 수 있음.
- 로컬 보조 인덱스
프로비저닝 vs 온디멘드
DynamoDB의 과금 방식중 온디멘드 방식과 프로비저닝 방식이 있다. 우리 서비스의 경우
- 트래픽이 점점 증가해나가고 있음, 또한 마케팅 여부에 따라 증가하거나 감소할 가능성이 있음.
- 스크래핑 작업 특성상, 한번 스크래핑이 시작하면 많은양의 읽기 쓰기가 동작되며, 최적화된 쓰기/읽기 유닛 책정이 어려움.
두가지 이유로 인해 읽기/쓰기 유닛을 책정하는 것보다는 온디멘드 방식을 사용하는 것이 좋다고 판단됌.
온디멘드 방식을 사용하게 되면, 읽기/쓰기 유닛을 효율적으로 사용하기 위한 테이블 설계에 대한 부담이 줄어 드는 장점도 있다.
테이블 설계
- DynamoDB 애플리케이션에서는 가능한 적은 수의 테이블을 유지해야 합니다. 대부분의 잘 설계된 애플리케이션은 단 하나의 테이블만 요구합니다.
- 쿼리를 처리할 때 데이터를 변화시키는 대신(RDBMS 시스템의 방식), NoSQL 데이터베이스는 데이터베이스의 모양이 쿼리 대상과 일치하도록 데이터를 구성합니다. 이는 속도와 확장성 향상에 중요한 요소입니다.
- 정렬 순서를 사용합니다. 핵심 설계가 함께 정렬할 것을 요구하는 경우, 관련 항목을 그룹으로 묶어 효율적으로 쿼리할 수 있습니다. 이는 중요한 NoSQL 설계 전략입니다.
파티션 키 설계
워크로드 배분
파티션 키 설계 : 트래픽이 하나의 항목으로 너무 집중되는 경우, 자주 액세스 하는 항목이 동일한 파티션에 상주하지 않도록 파티션 균형 재조정
-
파티션 키 값 균일성 사용자 ID, 애플리케이션의 사용자가 많은 경우. 좋음 상태 코드, 가능한 상태 코드가 몇 개 없는 경우. 나쁨 항목 생성 날짜, 가장 가까운 시간(예: 날, 시, 분)으로 반올림. 나쁨 디바이스 ID, 각 디바이스가 비교적 비슷한 간격으로 데이터에 액세스하는 경우. 좋음 디바이스 ID, 추적되는 디바이스는 많지만 다른 디바이스보다 한 디바이스가 훨씬 더 인기 있는 경우. 나쁨
쓰기 샤딩
여러 파티션 키 공간에 워크로드를 더 골고루 배분할 수 있도록, 파티션 키 값 끝에 난수나 접미사를 추가하여 병렬처리함
데이터 입력시, 가능하다면, 여러 파티션을 골고루 순회하며 입력할 수 있도록 쿼리
- 아래 표에서 첫번째 표보다, 두번째 표가 서로 다른 파티션 키 값을 사용, 병렬처리 성능 향상
UserID MessageID U1 1 U1 2 U1 … U1 … 최대 100 U2 1 U2 2 U2 … U2 … 최대 200 UserID MessageID U1 1 U2 1 U3 1 … … U1 2 U2 2 U3 2 … …
여러 UserID를 순회하면서 값을 입력한다면, 병렬 처리 성능이 향상한다.
정렬키 설계
https://docs.aws.amazon.com/ko_kr/amazondynamodb/latest/developerguide/bp-sort-keys.html
복합정렬키를 사용하면, 데이터의 계층적 관계를 정의할 수 있도록 도와준다
[country]#[region]#[state]#[county]#[city]#[neighborhood]위와같이, 정렬키를 구성한다면,
begins_with,between,>,<등 연산자를 사용하는 범위 쿼리를 사용하여 위치 목록을 효율적으로 범위 쿼리 할 수 있다.
보조키 설계
https://docs.aws.amazon.com/ko_kr/amazondynamodb/latest/developerguide/bp-indexes-general.html
일반적으로 로컬 보조 인덱스보다, 글로벌 보조 인덱스 사용
스토리지 및 IO 비용 감소를 위해 : 인덱스 수와 크기를 최대한 작게 유지
예시
Case1
https://docs.aws.amazon.com/ko_kr/amazondynamodb/latest/developerguide/bp-sort-keys.html
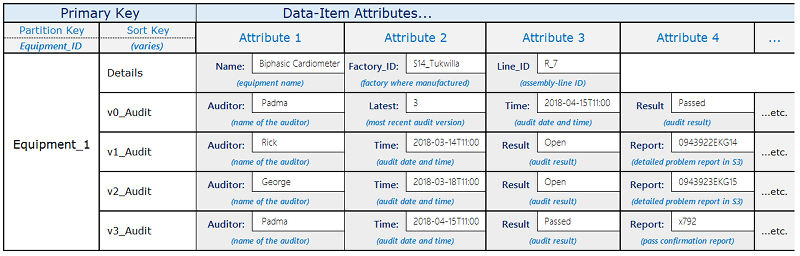
버전 관리에 정렬키를 사용하는 경우로 v0_ v00_ v000_ 같은 계층구조로 버전을 효율적으로 쿼링함.
Case2
https://dev.overnodes.com/entry/AWS-DynamoDBNoSQL

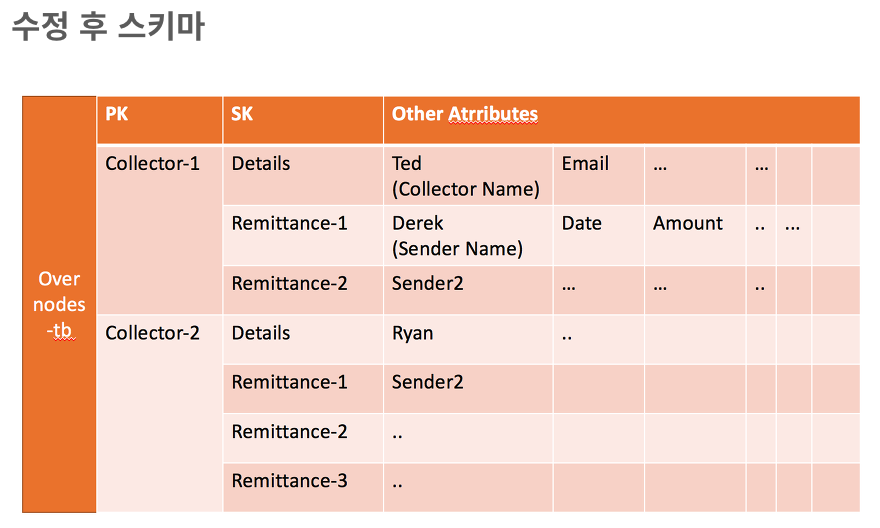
Collector-1 / Collector-2, Details/Remittance-1 키의 네임이 아니라, Value이다
스터디 적용
거래 태깅 변경 로그의 테이블 설계
파티션키, 정렬키 설계
키후보
파티션키 : 회사 ID / 정렬키 : 거래ID + 입력시간(DTS_UPDATE)
파티션키 : 거래 ID / 정렬키 : 입력시간(DTS_UPDATE)
파티션키 : 거래ID + 입력시간(DTS_UPDATE)
사용 쿼리
- 조회 쿼리
- 한 회사의 종합적인 태그 변경 로그를 분석할 경우 1번의 케이스가 적절
- 한 거래 내역의 태그 변경 로그를 쿼리할 경우 2번의 케이스가 적절
- 다중 입력시 병렬처리 성능 최적화 관점
- 1번 케이스의 경우, 스크래핑시나 스마트 태그시 한 파티션에 워크로드가 집중되는 문제가 있음
- 3번 케이스의 경우, 워크로드 분산에는 최적화되지만, 데이터의 구조가 실제 사용 케이스와 다름
- 2번 케이스가 적절함.
- 조회 쿼리
조회쿼리/다중입력을 고려하여 2번 케이스가 가장 적절하다고 판단됌.
보조키 사용
- 한 회사의 종합적인 태그 변경 로그를 분석할 케이스가 있을 수 있기 때문에
회사ID보조키를 사용한다. - 2번 케이스로 구성할경우, 회사 ID는 기본키와 별개이므로, 글로벌 보조키를 사용한다.